有向图的拓扑排序与最短路径问题
本文主要介绍了拓扑排序算法和非负权重图中的最短路径问题
拓扑排序
拓扑排序的核心思想,就是不断消除节点的前置依赖,没有前置依赖的节点(也即入度为0的点)的次序,一定先于有前置依赖的点。
这为算法的设计提供了入口:先找出所有入度为0的点,然后从图中去掉这些点,在新生成的图中重复以上步骤,直至遍历所有节点。
Show code (35 lines)
Algorithm: Topological_Sort(graph)
Input: A directed graph
Output: A linear ordering of vertices
Fn Topological_Sort(graph)
init an empty array in_degree[] (default set to 0)
init an empty array topo_order[]
init an empty queue Q
for each vertex u in G
for each vertex v in G.adj[u]
in_degree[v]++ // 遍历所有节点,建立入度表
endfor
endfor
for each vertex u in G
if(in_degree[u]==0):
Q.enqueue(u)
endif
endfor
while(Q is not empty):
currentNode=Q.dequeue()
topo_order.append(currentNode)
for each vertex k in G.adj[currentNode]:
in_degree[k]--
if(in_degree[k]==0):
Q.enqueue(k)
endif
endfor
endwhile
if (topo_order.size() < |V|):
return ERROR(Contains a circle) // 如果含有环,抛出异常
else return topo_order拓扑排序最常见的应用之一就是培养计划的课程设定。每一门课都是一个节点,先修要求就是一条有向边。通过拓扑排序,一般能得到一个比较合理的培养计划。当然,如果你的学校的培养计划比较抽象,那就难说了。🙃
非负权重最短路径问题
从一个源(source)出发,寻找源到达其他顶点的最短路径。(我们假设这是一个有向无环图)
基于拓扑排序的算法
既然我们在前面已经有了拓扑排序后的线性序列,那么我们可以直接利用它。在source之前的节点都是不可访问的,在source之后的节点且存在路径的节点显然都是可以访问的。
我们用dist[]代表到达某点的路长。每次更新路长都依赖下面这个核心公式:
dist[v] = min( dist[v] , dist[u] + weight(u,v) )下面是伪代码:
Show code (22 lines)
Algorithm DAG_Shortest_Path(graph, source)
Input: A DAG, a source vertex
Output: A array dist[] which stores the shortest path length
Fn DAG_Shortest_Path(G, s)
node_list=Topoligical_Sort(G)
init empty array dist[]
set dist[s] = 0
for each vertex u in G\{s}:
dist[u]= IFINITY
endfor
for each vertex v in G: // 这里利用dist[s]=0,开启前向更新,是一个trick
if (dist[v] != IFINITY):
for each vertex u in G.adj[v]:
dist[u]=min(dist[u], dist[v]+weight(v,u))
endfor
endif
endfor
return dist[]NOTE: 在这里有人可能会有一些疑惑。由于weight是不同的,先到达并不意味着路径最短。如果某个点的最短路径改变了,是否下游节点同样需要全部更新?
实际上,拓扑排序恰恰完美解决了这个问题。它的关键性质是:
对于边(u, v),在拓扑排序中,u 一定出现在 v 之前。
这意味着当你访问到节点v时,你已经把他的全部可能前驱 u1, u2, u3… 都访问了一边,那么最终得到的dist[v]一定是最佳的结果。
关于时间复杂性,这里的操作分为“边”操作和“点”操作,最终所有的边和点都会不重复地操作一次。所以最终的时间复杂度就是 O(V+E)
基于贪心策略的 Dijkstra 算法
基于拓扑排序的算法为我们解决了节点次序问题,所以我们不需要额外去更新下游节点。不过拓扑排序只能处理有向无环图,对于更多的图,一种更一般的算法是 Dijkstra 算法。
算法核心区是采用以这样一种贪心策略:
对于尚未确定最短路径的点,优先选择当前距离起点最近的点。
这里体现出的是以局部最优构建全局最优的贪心思想。
需要强调的是,也正是为了达到这种目的,算法使用的队列不是一般的FIFO队列,而是 Prority Queue (优先级队列)。这样元素在入队时就已经完成了排序操作。
Show code (29 lines)
Algorithm: Dijkstra_Shortest_Path(graph, source)
Input: A graph with non-weights edge and a source vertex
Ouput: A array dist[] which stores the shortest path of each vertex
Fn Dijkstra_Shortest_Path(G, s)
init an empty array dist[]
init an empty prority queue Q
dist[s] = 0
for each vertex u in G\{s}:
dist[u]=IFINITY
endfor
Q.enqueue({0,s}) // 将起点加入队列
while(Q is not empty):
{d, u} = Q.pop() // 弹出 d 值最短的节点,也就是距离最近的点
if (d > dist[u]):
continue // 如果已经有了更优选择,就不需要继续更新
else:
for each vertex v in G.adj[u]:
if dist[v] > dist[u] + weight(u, v):
dist[v] = dist[u] + weight(u, v)
Q.enqueue({dist[v], v})
endif
endfor
endif
endwhile
return dist[]我们可以以一个例子来演示:
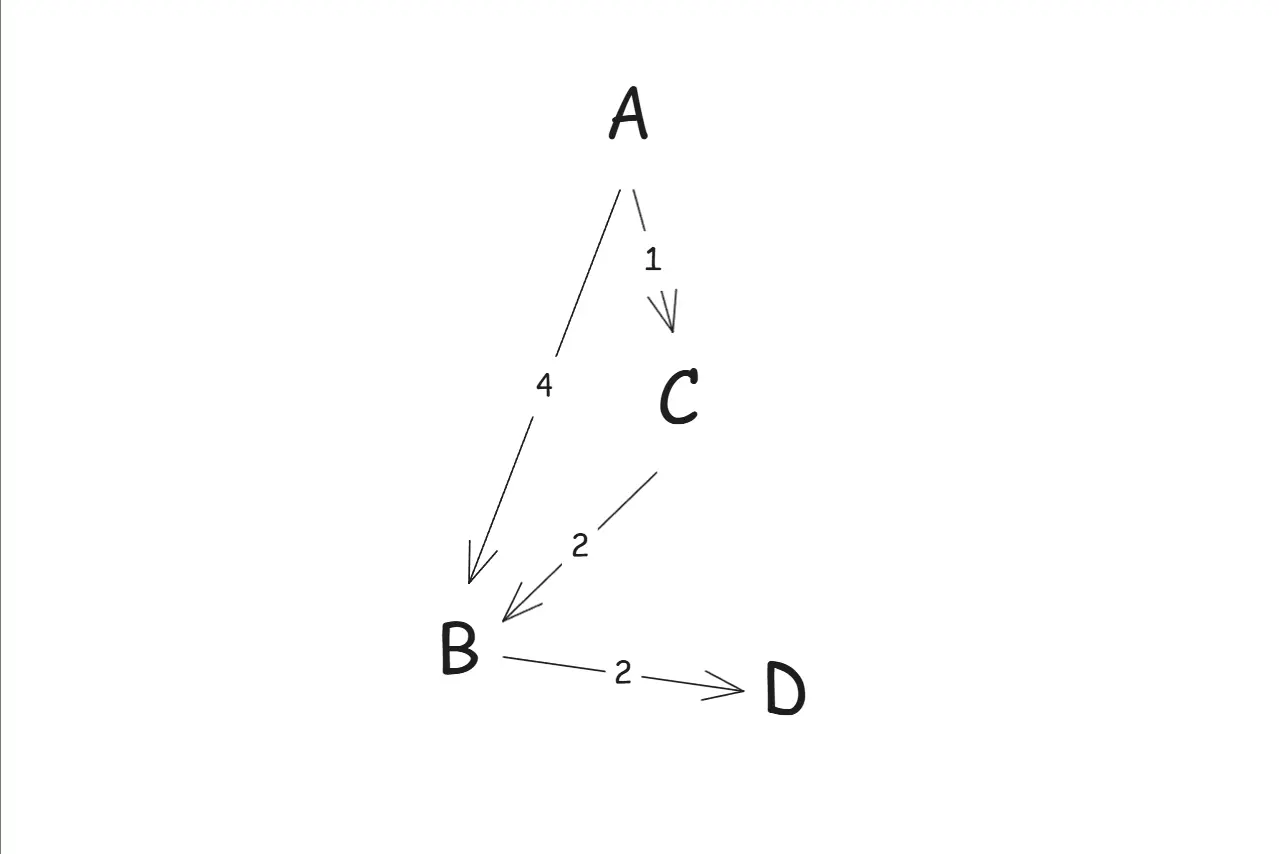
- 从 A 点出发,此时队列中是 {0, A}
- A 点弹出队列,遍历它的两个邻居 B 和 C, 于是栈中有 {1, C}, {4, B}
- 下一次出队的就是 C 点, 它会去更新 B 点,于是 B 点带着新路长入队 {3, B}
- 下一次出队的是 B 点,但是注意,由于是优先级队列,这时的 d 值就是 3 了。它会去更新 D 点 {5, D}
- 下一次出队的还是 B 点,不过。它存储的 d 值是旧的值, 4>3, 所以直接跳过了
- 下一次出队的是 D 点,没有下游,直接 continue
- 队列为空,退出
于是我们就得到了各个点的dist值:
- A: 0
- B: 3
- C: 1
- D: 5
这个算法精髓在于,不断取最短路径,所以我们确保在确定dist[D]时,B 点已经是最短路径了。从而避免dist[B]更新后,下游需要再次遍历更新。
对于 Dijkstra 算法的时间复杂度:
算法每一步都要从队列弹出一个当前距离最短的节点u, 一般我们优先级队列使用的是二叉堆结构,每次出堆并重新调整的成本是 O(logV). 于是总成本: |V| * O(logV) = O(VlogV)
如果一条边dist值发生了更新,就需要入队,这个成本也是 O(logV),最坏情况下,每条边都要处理,总成本: |E| * O(logV) = O(ElogV)
全部加起来,就是 O((V+E)logV). 在一个连通图中, |E|通常大于等于 |V| -1, 所以我们常常简写为: O(ElogV)